
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- convergence
- Fairness
- value shaping
- ML
- free rider
- ordered dropout
- 개인정보
- deep learning
- OOD
- DP
- OSR
- FedProx
- Agnostic FL
- FL
- Open Set Recognition
- q-FedAvg
- Machine learning
- Federated Learning
- PPML
- 연합학습
- 딥러닝
- data maximization
- 기계학습
- Analysis
- Differential Privacy
- 머신러닝
- FedAvg
- q-FFL
- OoDD
- Federated Transfer Learning
- Today
- Total
Federated Learning
[ICLR 2023] FedOV - (2) 본문
논문 제목: Towards Addressing Label Skews in One-Shot Federated Learning
출처: https://openreview.net/forum?id=rzrqh85f4Sc
지난 포스트에서 저자들이 어떠한 이유로 FL에 OSR을 적용하려고 하였는지 확인하였습니다. (이전 글 보기) 이번 포스트에서는 PROSER를 FL에 implement하는 과정에서 생긴 문제점을 어떻게 해결하고자 하였는지 알아보도록 하겠습니다.
5. Data Destruction (DD)

앞서 살펴보았듯이, PROSER의 Manifold Mixup을 FL setting에서 그대로 사용할 경우 문제가 발생할 소지가 있습니다. 각 device가 가지고 있는 data 수도 많지 않을뿐더러, device별로 data distribution도 다르기 때문에 pathologic한 setting(가령, 각 device마다 1개 혹은 2개의 class에 해당하는 data만을 가지고 있는 경우)에서는 outlier generation이 제 기능을 하기 어렵기 때문입니다. 따라서, 저자들은 Manifold Mixup 외의 추가적인 outlier generation 방법을 고민하였습니다.
오른쪽 그림은 MNIST, Fashion-MNIST, CIFAR dataset의 일부에 대하여 Dara Destruction(DD)을 적용하여 outlier data를 generate한 결과입니다. (제일 왼쪽 column은 원본 data입니다.) DD의 idea는 "data의 class를 유추할 수 있는 key feature를 파괴하되, 그외의 자잘한 feature는 살리자"는 것입니다. 쉽게 말해서, DD는 과격한 data augmentation인 셈입니다.
DD의 자세한 components는 다음과 같습니다: (torchvision.transforms로 구현되었습니다.)
- RandomResizedCrop: 원본 image의 1% ~ 33%에 해당하는 부분을 crop한 후, 이를 원본 image와 동일한 크기로 resize합니다.
- GaussianBlur: 최소 1 * 3, 최대 5 * 9 크기의 kernel을 이용하여 blurring하며, σ∈[10,100]입니다.
- RandomErasing: 원본 image의 33% ~ 50%에 해당하는 부분을 지워버립니다.
- RandomCopyPaste: 원본 image를 상하 혹은 좌우로 자른 뒤, 둘 중 하나를 택하여 반대쪽에 붙여 넣습니다.
- RandomSwap: 원본 image를 상하 혹은 좌우로 자른 뒤, 이 둘을 서로 뒤바꿉니다.
- RandomRotation: 원본 image에서 정사각형 모양으로 두 부분을 선택한 후, 각각 rotation을 적용합니다.
이 중, 위 세 가지는 기존에 사용되던 augmentation 기법에서 비정상적인 hyperparameter를 사용한 것이고, 아래 세 가지는 저자들이 새로이 제안한 기법입니다. 저자들은 모든 train data에 여섯 가지 중 한 가지를 random하게 (이는 RandomChoice로 구현되었습니다.) 적용하여 outlier를 generate하였습니다. (이러한 저자들의 주장과 달리, 위의 그림에서는 여러 개의 기법이 함께 사용된 것을 확인할 수 있습니다. 구현된 code를 보면, 처음에는 위 그림과 같이 한 번에 다양한 기법들을 적용할 생각이었던 것 같습니다. 하지만 실제로는 한 번에 한 가지 DD 기법만 사용됩니다.)
6. Adversarial Outlier Enhancement (AOE)
저자들은 DD로 만들어진 outlier로 만족하지 못한 듯합니다. Adversarial Training(AT) 기법을 활용하여 보다 그럴싸한 outlier를 generate해보기로 하는데, 이 방식을 Adversarial Outlier Enhancement(AOE)라고 명명하여였습니다.
AOE의 idea는 "AT는 model이 높은 confidence로 잘못 분류하도록 설계된 adversarial samples를 training 과정에서 함께 보여주는 것인데, DD로 만들어진 outlier가 model을 속이는 과정을 더 잘 돕기 위하여 이 과정을 적용하자"는 것입니다. 즉, AOE는 DD로 만들어진 outlier에 추가적으로 적용되는 기법입니다.
오른쪽 그림은 앞서 살펴 본 DD로 만들어진 outliers에 AOE를 적용한 것입니다. MNIST의 0 data를 6과 비슷하게, 그리고 2 data를 3과 비슷하게 만든 것을 확인할 수 있습니다. 이처럼 AOE는 더욱 그럴싸한 outliers를 만드는 역할을 수행합니다.
AOE에 사용된 AT 기법은 FGSM[1]이며, 이에 관한 자세한 내용은 해당 paper를 참고하시기 바랍니다.
7. PROSER에 DD와 AOE를 적용한 결과
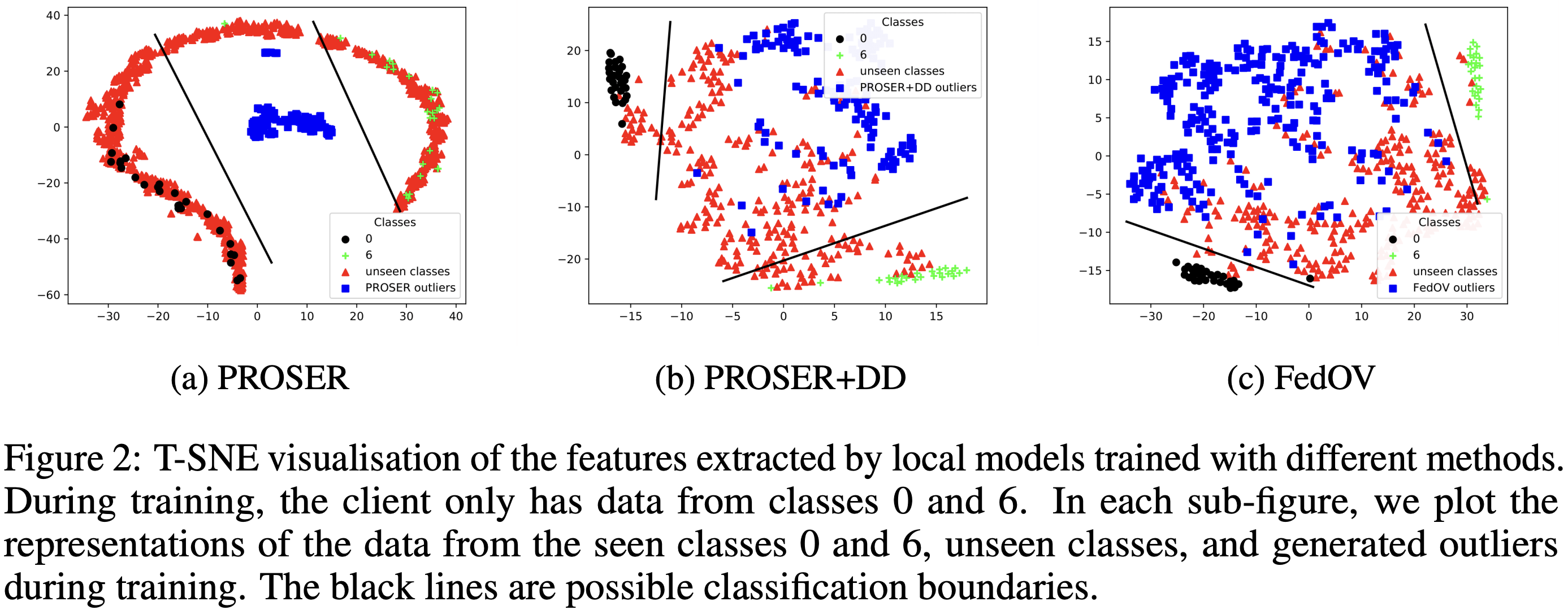
위 그림은 local client가 MNIST dataset 중 class 0, 6에 해당하는 data만 갖고 있는 상황에서 실험한 결과입니다. 우선 (a)는 vanilla PROSER를 사용한 경우인데, PROSER의 설계 상 generated outliers가 가운데에 모이고 known classes가 이를 둘러싼 모습을 확인할 수 있습니다. 다만, 실제 unseen classes(0, 6을 제외한 MNIST class)와 generated outliers의 분포와 일치하지 않으며, 오히려 unseen classes와 known classes의 분포가 겹치는 모습을 확인할 수 있습니다.
다음으로, (b)는 PROSER와 DD를 함께 사용한 경우입니다. 추가적인 loss로 인하여 원하여 generated outliers를 known classes가 둘러싸는 모습은 사라졌습니다. 그리고 (a)에 비하여 known과 unknown을 잘 구분하고 있는 모습을 확인할 수 있습니다. 다만, generated outliers와 unseen classes 의 분포가 (모여 있기는 하지만) 다소 분리되어 있다는 점은 아쉽습니다.
마지막으로, (c)는 PROSER에 DD와 AOE를 모두 적용한 것입니다. 즉, FedOV와 동일한 setting입니다. generated outliers와 unseen classes 의 분포가 (b)보다 조금 더 가까워졌지만, 아직 둘 사이의 거리감이 보이기는 합니다. 대신 known과 unknown 사이의 threshold가 더욱 더 tight해진 모습을 확인할 수 있습니다.
8. FedOV의 Pseudo Code

최종적인 FedOV의 pseudo code는 다음과 같습니다. (해당 paper는 0,1,⋯,c−1 class를 known으로, c class를 unknown으로 denote하며, unknown class가 여러 개인 경우는 고려하지 않고 있습니다.) 각 client에서의 학습 과정에서는 특이사항이 없으며, 우리가 주목하여야 하는 부분은 server에서의 aggregation 과정입니다. 일반적인 FL setting과는 다르게 voting으로 prediction이 이루어진다는 것이 해당 mechanism(을 위시한 많은 One-Shot FL)의 특이사항인데, Line 16을 보면 voting 과정에서 c (즉, unknown) class의 probability를 제외하고 계산합니다. 이를 위해서 OSR methods를 적용한 것이죠. 만약 voting 이후에 ensemble model이 너무 커서, 혹은 이 model을 기반으로 One-Shot 이후의 추가적인 FL을 수행하고자 model을 하나로 합치려고 한다면, Knowledge Transfer를 고려할 수도 있습니다.
다음 포스트에서는 해당 paper의 experiments를 살펴보도록 하겠습니다. 저자들이 많은 experiments를 수록한 관계로, 중요한 결과 위주로 선별하여 설명할 계획입니다.
참고 자료:
[1] [ICLR 2015] https://arxiv.org/abs/1412.6572
'Federated Learning > Papers' 카테고리의 다른 글
| [ICLR 2023] FedOV - (3) (0) | 2023.04.01 |
|---|---|
| [ICLR 2023] FedOV - (1) (0) | 2023.03.12 |
| [FL-NeurIPS 2022] Data Maximization - (6) (0) | 2023.01.24 |
| [FL-NeurIPS 2022] Data Maximization - (5) (0) | 2023.01.19 |
| [FL-NeurIPS 2022] Data Maximization - (4) (1) | 2023.01.14 |



