
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- q-FFL
- ordered dropout
- Fairness
- 머신러닝
- DP
- FedProx
- PPML
- value shaping
- FedAvg
- 연합학습
- OOD
- ML
- Differential Privacy
- free rider
- Open Set Recognition
- Federated Transfer Learning
- data maximization
- 딥러닝
- Agnostic FL
- 개인정보
- OoDD
- deep learning
- FL
- Machine learning
- q-FedAvg
- 기계학습
- convergence
- Analysis
- OSR
- Federated Learning
- Today
- Total
Federated Learning
[ICLR 2023] FedOV - (3) 본문
논문 제목: Towards Addressing Label Skews in One-Shot Federated Learning
출처: https://openreview.net/forum?id=rzrqh85f4Sc
지난 포스트에서 추가적인 outlier generation methods인 DD와 AOE에 관하여 알아보았습니다. (이전 글 보기) 이번 포스트에서는 해당 paper의 experiments를 살펴보도록 하겠습니다. 앞서 언급하였듯이 모든 실험 결과를 다루기는 어려우므로, 추가적으로 궁금하신 사항이 있을 경우 paper를 참고해주시기 바랍니다.
9. Experiments
(1) Settings

사용된 dataset은 위의 표와 같습니다. 별도의 언급이 없는 한 총 10개의 client가 학습 과정에서 참여하며, $\mathcal{L}_\text{PROSER}$의 hyperparameters는 $\beta = 0.01$, $\gamma = 1$로 지정하였습니다. AOE를 위한 FGSM은 5회 반복 수행하며, 이때의 step size는 0.002로 설정하였습니다. DD 과정에서 사용되는 augmentation 기법은 이전 포스트에서 자세히 설명하였으므로 생략합니다. 그리고 별도의 언급이 없는 한 모든 실험은 FedAvg paper에서 사용한 simple CNN model을 사용하여 수행하였습니다.
(2) Overall Results

위 표는 FedOV의 전반적인 성능을 report한 것입니다. (metric은 global model의 test accuracy입니다.) 표에서 앞의 두 column, 뒤의 두 column이 One-Shot FL 혹은 Voting에 기반을 둔 기법들이므로, 이 네 가지를 중점적으로 보시면 됩니다. 다른 기법들은 성능이 제대로 나오지 않고 있는데, 이는 한 round만 진행했을 때의 결과이기 때문입니다. 저자들은 "FedOV의 One-Shot 능력이 우수하다"는 것을 보이고 싶었겠지만, 일반적인 FL 방법들과 성능을 비교하는 것은 공평하지 못하다는 생각이 듭니다. 어찌됐든, 한 round만 진행한 상황에서는 FedOV가 모든 경우에 대하여 outperform하는 모습을 보이고 있으며, 특히 $\#C = 1$, 즉, 각 client마다 1개의 class에 해당하는 data만 가지고 있는 상황에서 FedOV는 독보적인 성능을 보여줍니다. 이는 OSR 기법을 활용하여 각 local model의 overconfidence를 잘 잡아주었기 때문이라고 볼 수 있으며, 이 부분이 해당 paper의 의의입니다.
(3) Outlier Generation의 효용
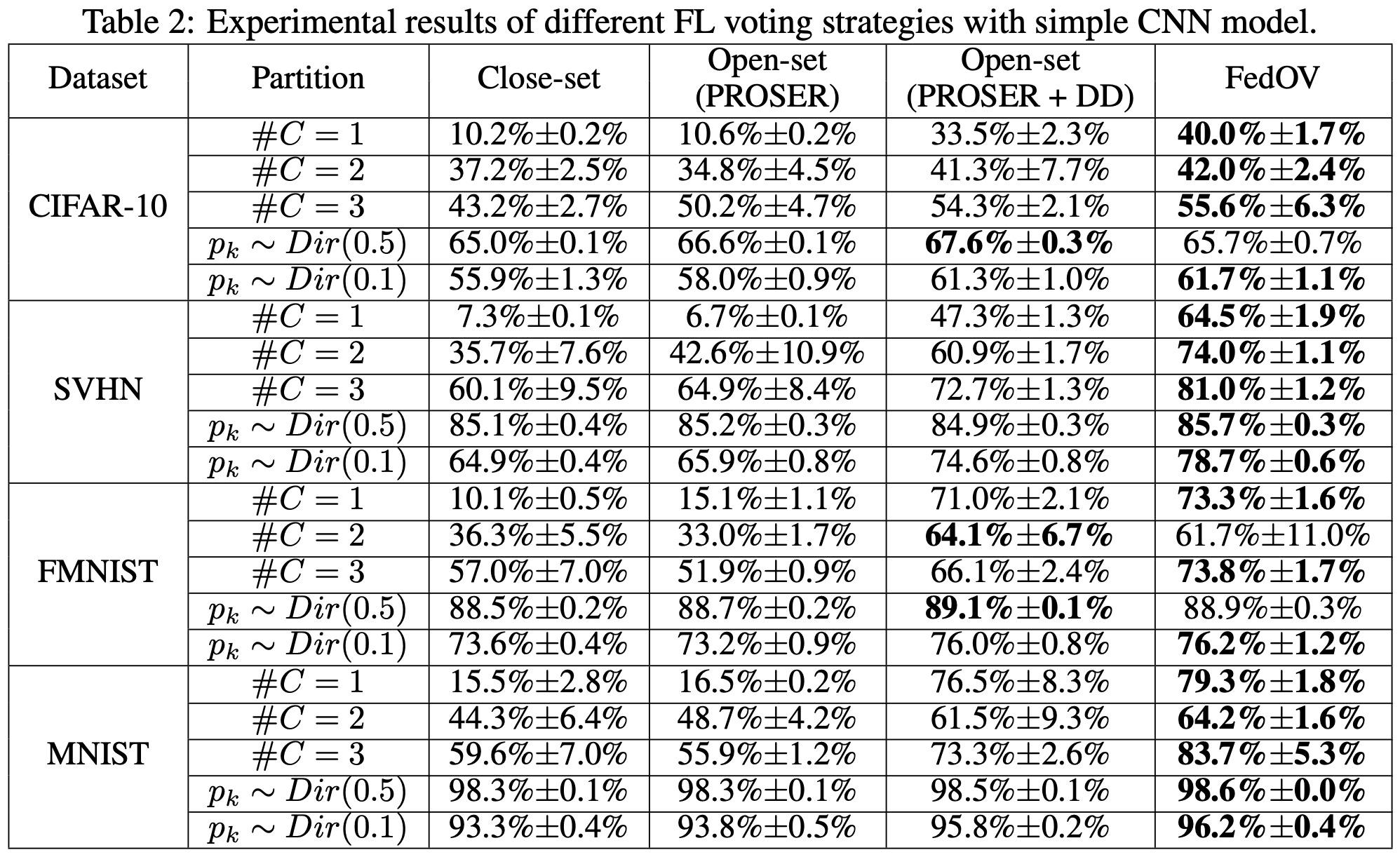
다음은 PROSER, DD, AOE가 각각 만들어내는 outliers의 효용을 평가한 실험합니다. 일반적으로는 모두 사용한 것이 가장 좋은 성능을 보였지만, 간혹 AOE를 사용하면서 성능이 떨어지는 경우도 존재하였습니다. 하지만 PROSER만을 사용한 경우 어떠한 setting에서도 가장 좋은 performance를 보여주지 못하였는데, 이는 FL이라는 특수한 환경에 기인한 것으로 보입니다.
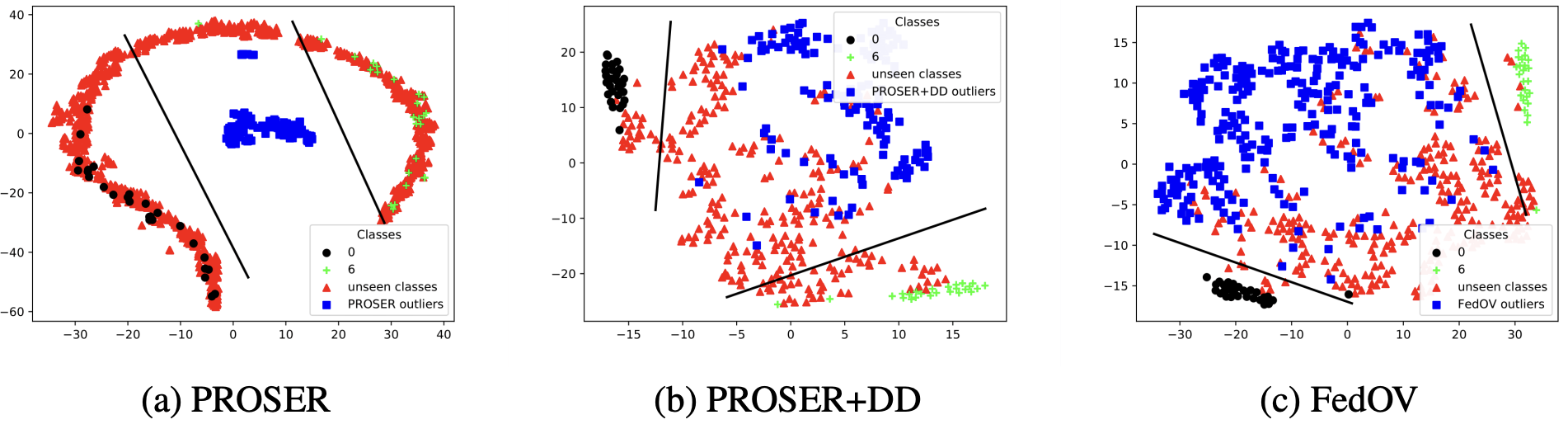
아래의 그림은 PROSER, DD, AOE를 적용하였을 때, MNIST의 0과 6 에 해당하는 data만을 가진 local client의 data distribution이 어떻게 변하는지를 묘사한 t-SNE visualization입니다. $(a)$를 보면, PROSER가 만들어낸 outliers를 0과 6 class data가 원형으로 둘러싸고 있는 모습을 확인할 수 있으며, 이는 $\mathcal{L}_\text{PROSER}$의 정의 상 자명합니다. 문제는, 해당 client가 가지고 있지는 않으나 다른 client가 가지고 있는 class (즉, class 1, 2, 3, 4, 5, 7, 8, 9) 역시 outliers를 둘러싸고 있다는 것입니다. (이러한 class를 unseen이라고 칭하겠습니다.) 이들은 해당 client에게는 outlier에 해당하므로 PROSER가 만들어낸 outliers와 같은 분포 상에 존재하는 것이 바람직하겠지만, 이상하게도 이들은 known classes처럼 행동하고 있습니다. 왜 이러한 일이 일어났을까요?
그 이유는, FL setting에서는 두 가지 종류의 unknown이 존재하기 때문입니다. 다시 말해, unseen class도 해당 client에게는 unknown이고, class 0 ~ 9 이외의 임의의 data 역시도 unknown입니다. PROSER는 FL setting을 염두에 두고 만들어진 method가 아니기 때문에 당연히도 이 부분을 적절하게 해결해주지 못하였고, 그 결과 $(a)$처럼 generated outlier와 unseen data가 별도의 distribution을 보이게 된 것입니다. 반면, $(b)$와 $(c)$를 보면 DD와 AOE에 의하여 만들어진 outliers는 unseen classes와 비슷한 분포를 보이는 것을 확인할 수 있습니다. 즉, DD와 AOE가 서로 다른 두 종류의 unknown을 하나로 묶어주는 역할을 수행하고 있는 셈입니다.
(4) Centralized Setting에서의 DD와 AOE
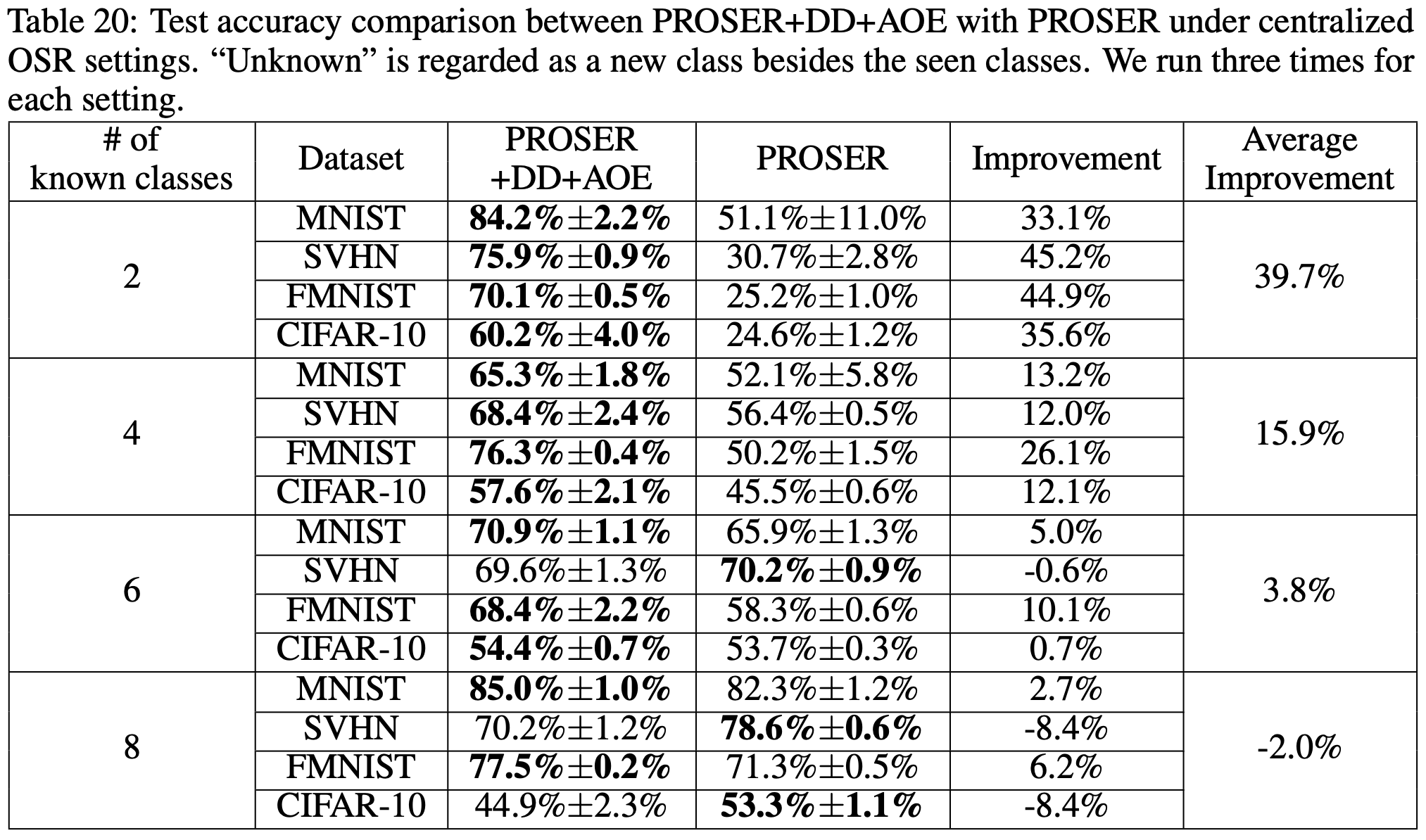
다음 표는 FL setting이 아닌 일반적인 case에서 PROSER에 DD와 AOE를 함께 사용할 경우의 성능 변화를 정리한 것입니다. 모든 dataset에서 known의 비율이 작아질수록, 즉, Openness가 커질수록 성능 향상 폭이 커지는 경향을 보여주고 있습니다. 이것은 곧 DD와 AOE가 (각 client마다 data distribution이 상이한) FL에 적합한 outlier generation 기법임을 의미하기도 하며, 이와 동시에 centralized setting에서 PROSER를 사용할 때에 상황에 따라 DD와 AOE를 함께 사용하는 것이 도움이 될 수도 있다는 것을 보여주는 증거이기도 합니다.
(5) 참여하는 Client의 수가 많을 때
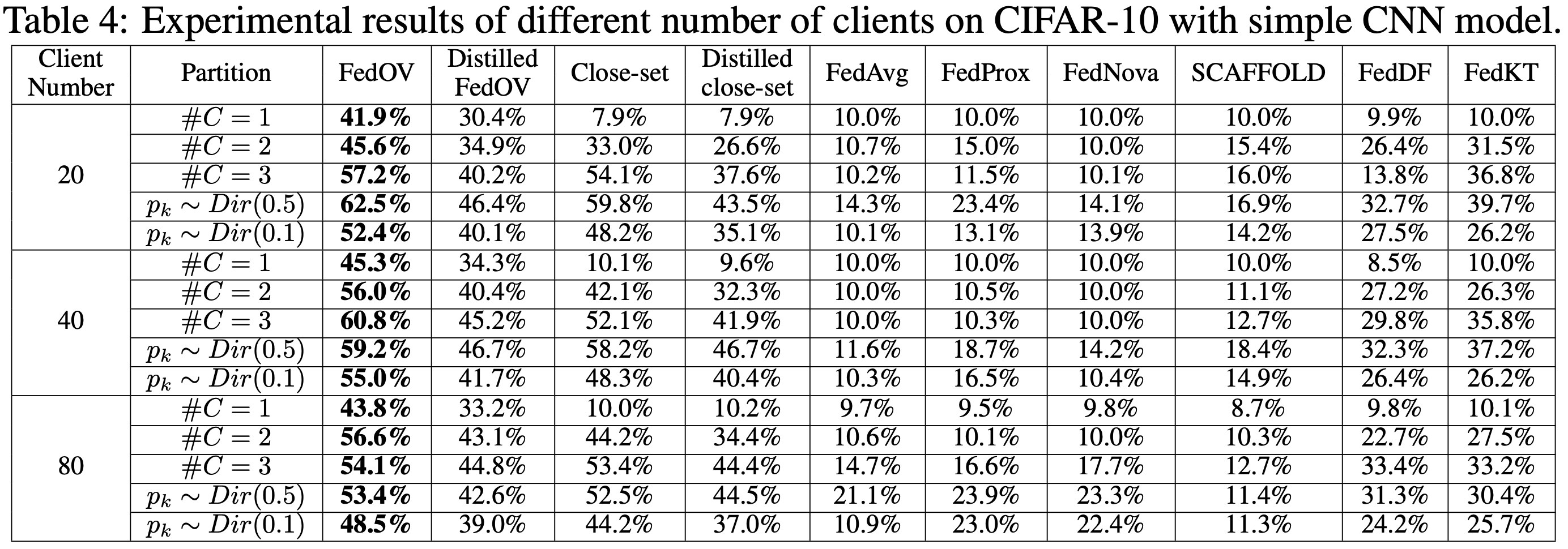
다음은 FedOV가 cross-device setting에서도 사용 가능한지에 관한 실험 결과입니다. 충분히 좋은 성능을 보이고 있는 관계로, 추가적인 설명은 생략하도록 하겠습니다.
(6) Iterative Methods와의 비교
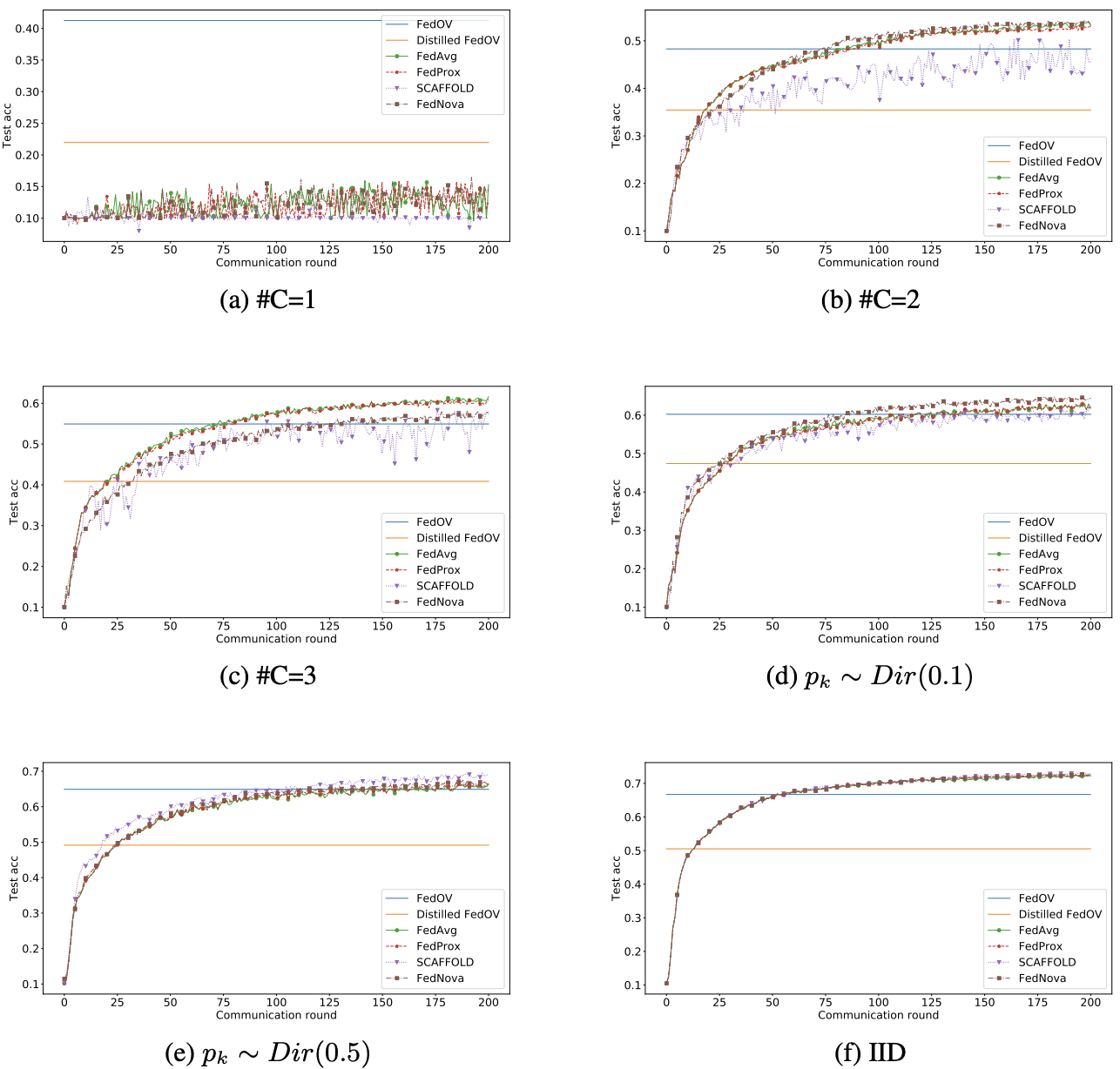
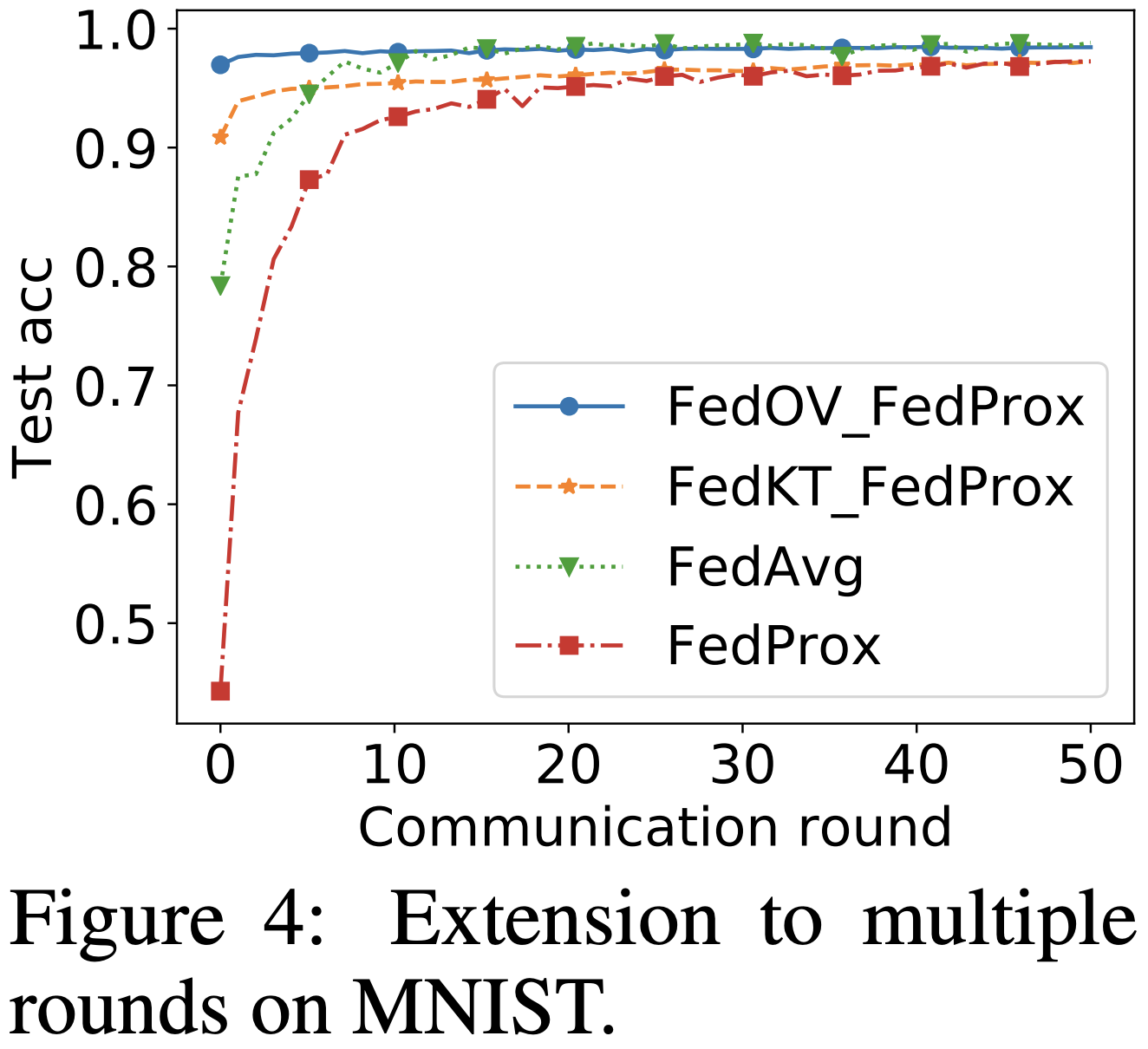
위 그래프는 FedOV, Distilled FedOV를 일반적인 (multiple round communication을 진행하는) FL 기법들과 비교한 것입니다. 별 수 없는 $\#C = 1$ case를 제외하면, 언젠가는 FedOV가 다른 기법들에게 따라잡히는 모습을 확인할 수 있습니다. 이 지점이 FedOV의 명확한 한계라고 할 수 있습니다. 다만, 1 round에서의 성능은 FedOV가 월등하게 좋기 때문에, 오른쪽 그래프와 같이 FedOV로 적절하게 initialization 한 후에 다른 FL 기법들로 finetuning을 하는 것은 충분히 고려해볼 수 있습니다. 이 그래프 상에서는 FedOV_FedProx가 결국 FedAvg에게 따라잡히는 모습을 보이지만, 이 둘이 비슷한 수준의 test accuracy에 도달할 때까지 걸리는 시간이 유의미하게 차이나기 때문에, FedOV Initialization은 현업에서 유용하게 사용될 것으로 보입니다.
(7) 학습 시간 비교


왼쪽의 표는 RTX 3090 GPU 1장으로 CIFAR-10 data를 학습하였을 때 소요되는 시간을 비교한 것입니다. FedAvg와 비교하였을 때에는 약 2배, FedProx와 비교하였을 때에는 약 1.5배 차이가 나는 것을 확인할 수 있는데, 앞서 (6)에서 이야기한 "유의미한 시간 차이"를 다시 한 번 확인해볼 수 있는 부분입니다. 다음으로, 오른쪽의 표는 DD와 AOE가 학습 시간에 어느 정도의 영향을 미치는지 분석한 결과입니다. 대략 2배 정도 시간 차이가 나는데, 이는 왼쪽에서 확인한 시간 차이의 원인이 DD와 AOE에 있음을 의미한다고 볼 수 있습니다. PROSER는 그다지 학습 시간에 영향을 주지 않은 것으로 보이는데, 이는 이전에 PROSER 포스트에서 살펴본 내용과 일맥상통하는 부분입니다.
10. 의의 및 한계
해당 paper는 OSR 기법을 적절히 활용하여 Voting에 기반한 One-Shot FL setting에서 각 client가 overconfident하다는 문제점을 해결하였다는 점에서 의의를 갖습니다. 하지만 너무나도 제한적인 setting에서만 유의미한 효력을 갖기 때문에, 이 paper의 한계 역시 명확합니다. 그럼에도 FL에서 OSR을 사용하고자 할 때 발생할 수 있는 여러 문제점을 분석하였다는 점, Distilled FedOV를 통하여 Initialization을 더욱 용이하게 할 수 있다는 점 등에서 One-Shot setting을 벗어난 일반적인 FL 기법들에 대해서도 어느 정도 긍정적인 영향을 주었다고 볼 수 있는 여지도 존재합니다.
'Federated Learning > Papers' 카테고리의 다른 글
| [ICLR 2023] FedOV - (2) (0) | 2023.03.14 |
|---|---|
| [ICLR 2023] FedOV - (1) (0) | 2023.03.12 |
| [FL-NeurIPS 2022] Data Maximization - (6) (0) | 2023.01.24 |
| [FL-NeurIPS 2022] Data Maximization - (5) (0) | 2023.01.19 |
| [FL-NeurIPS 2022] Data Maximization - (4) (1) | 2023.01.14 |



