
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- free rider
- Differential Privacy
- 개인정보
- 딥러닝
- 기계학습
- Federated Transfer Learning
- Analysis
- OSR
- convergence
- FedProx
- 머신러닝
- q-FedAvg
- ML
- PPML
- OoDD
- 연합학습
- OOD
- Open Set Recognition
- FedAvg
- value shaping
- Federated Learning
- data maximization
- Agnostic FL
- DP
- deep learning
- ordered dropout
- Machine learning
- q-FFL
- FL
- Fairness
- Today
- Total
Federated Learning
[AAAI 2022] SplitFed - (1) 본문
논문 제목: SplitFed: When Federated Learning Meets Split Learning
출처: https://arxiv.org/abs/2004.12088
이번에 가져온 논문은, 이전까지 제가 잘 다루지 않던 privacy preserving에 관한 내용을 담고 있습니다. accepted된 지 얼마 되지 않은 최신 논문인 만큼, 기존에 등장하였던 다양한 방법론들이 적용된 알고리즘을 제시하고 있습니다. 특히, 그중에서도 Split Learning(SL)이라는 개념은 Federated Learning 이후에 제시된, 비교적 최신의 분산학습 체계입니다. 서로 다른 두 분산학습 방식인 SL과 FL을 엮은 해당 논문이 과연 어떠한 novelty를 가지고 있을지 확인해보도록 하겠습니다.
1. Split Learning이란? / Federated Learning과의 차이는?

위 그림[1]은 Split Learning의 다양한 유형을 도식화한 것입니다. 세 그림의 공통적인 특징이 있다면, 특정 지점(초록색 layer)에서 Client와 Server 간의 통신이 이루어진다는 것입니다. 해당 지점을 Cut Layer라고 부르며, Client가 Cut Layer 이전까지 local에서 학습을 진행하면, Server에서 그때까지의 학습 결과(이를 Smashed Data라고 지칭합니다)를 받아와서 마저 학습을 수행하는 구조입니다. 즉, 이름 그대로 model을 split하는 기법입니다. SL이 FL과 동일하게 원본 데이터를 서버에 전송하지 않아도 된다는 이점을 가지고 있다는 점을 알 수 있는 부분이며, 그와 동시에 FL과 SL의 차이가 발생하는 지점도 이 부분입니다.
FL은 local device에서 모든 학습이 이루어진 후, 학습 결과를 server에 반환하는 구조입니다. local device가 충분한 computing power를 가지고 있다면 다행이지만, 스마트워치와 같은 기기들은 컴퓨터 등에 비하여 computing power가 부족하기 때문에 상황에 따라 모든 학습을 진행하기 어려울 수도 있습니다. (특히, 딥러닝 모델의 경우가 그러합니다.) 또한, FL의 경우 Server 관리자가 악의적인 마음을 가지고 있다면 얼마든지 model에 접근할 수 있다는 보안 상의 문제점도 가지고 있습니다.
하지만 SL의 경우 모델의 shallow한 부분만 local에서 학습을 진행하고, deep한 부분은 server의 몫으로 돌리면서 computational한 한계를 극복할 수 있습니다. 그리고 학습 과정을 두 부분으로 분리하기 때문에, Server에서 Client의 model에 (그리고 Client에서 Server의 model에) 접근할 수 없다는 보안 상의 이점도 존재합니다.
다만, SL은 치명적인 문제점 한 가지를 가지고 있는데, Server가 한 Client에 대한 학습을 진행하는 동안 다른 Client들은 놀고 있어야 한다는 것입니다. 오른쪽에 있는 Split Learning의 pseudo code[2]를 보면, 학습할 차례가 된 Client는 Server로부터 이전 Client의 학습 결과를 받아와서 사용하는 것을 알 수 있습니다. (Alice가 Client, Bob이 Server에 해당합니다.) 즉, 학습이 sequantial하게 이루어지고 있고, 따라서 SL은 그 구조적인 한계 때문에 parallel하게 학습이 진행되는 FL보다 느리게 학습될 수밖에 없습니다.
2. Splited Federated Learning (SplitFed, SFL)
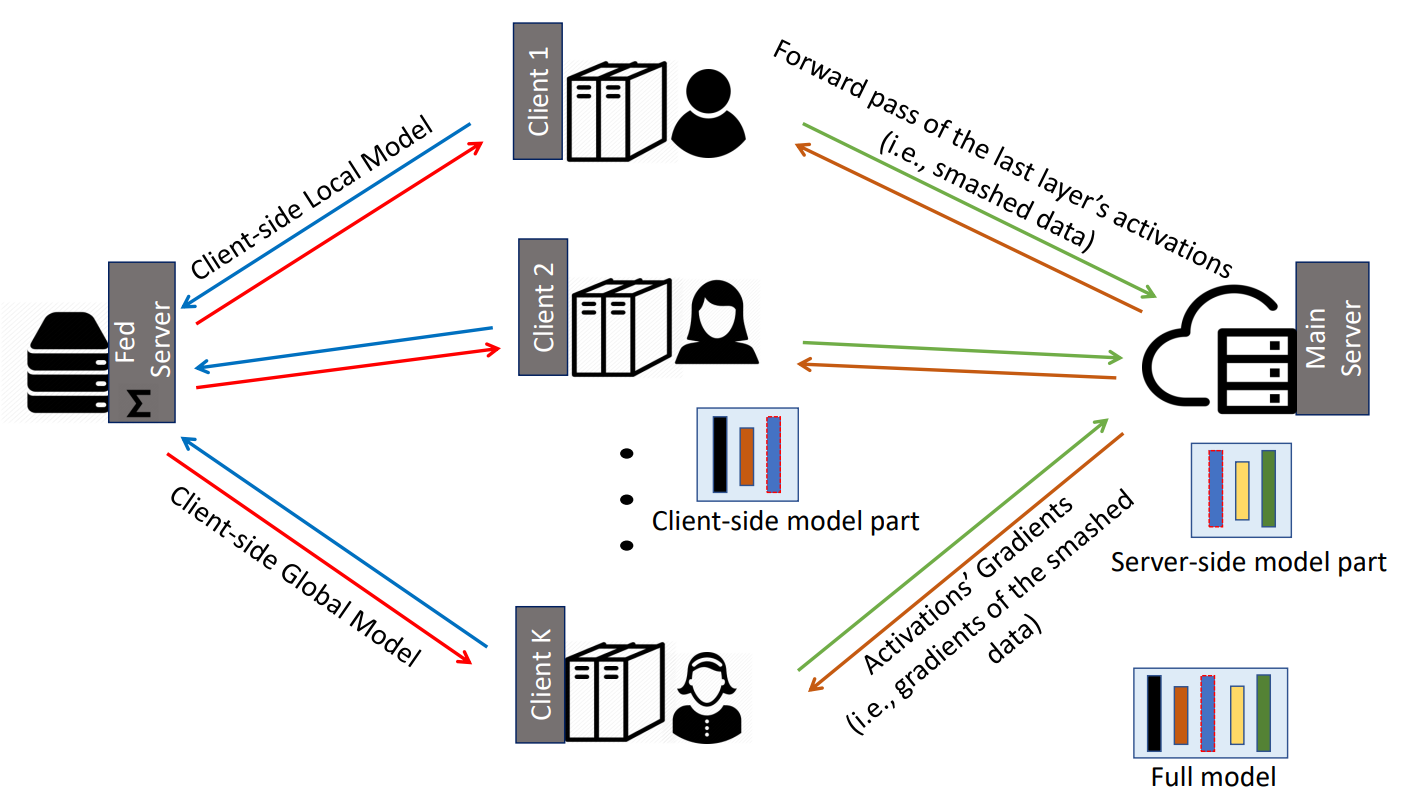
저자들이 해당 논문에서 제안하는 알고리즘인 SFL은 SL을 위한 Main Server와 FL을 위한 Fed Server를 각각 사용합니다. 우선, 각 Client가 Cut Layer까지 forward propagation을 진행하고, 그 결과인 Smashed Data를 Main Server로 반환합니다. 그러면 Main Server에서는 Smashed Data의 forward propagation을 마저 진행한 후, 다시 Cut Layer까지 backpropogation을 수행합니다. 이를 다시 각 Client에게 반환해주면, Client는 마저 backpropogation을 진행한 후, 그 결과를 Fed Server로 반환합니다. Fed Server는 FedAvg 등의 aggregation method를 통하여 global update를 수행한 후, 그 결과를 학습에 참여한 모든 Client에게 전송합니다. 이것이 전반적인 SFL의 workflow이며, Differencial Privacy 등을 이용하여 Privacy Preserving을 용이하게 하거나, 동형암호 등을 적용하여 정보를 암호화한 뒤에 Fed Server가 해야 할 일을 (하나의 Server만을 사용하기 위하여) Main Server에서 수행하게 하는 등의 변화를 줄 수도 있습니다.

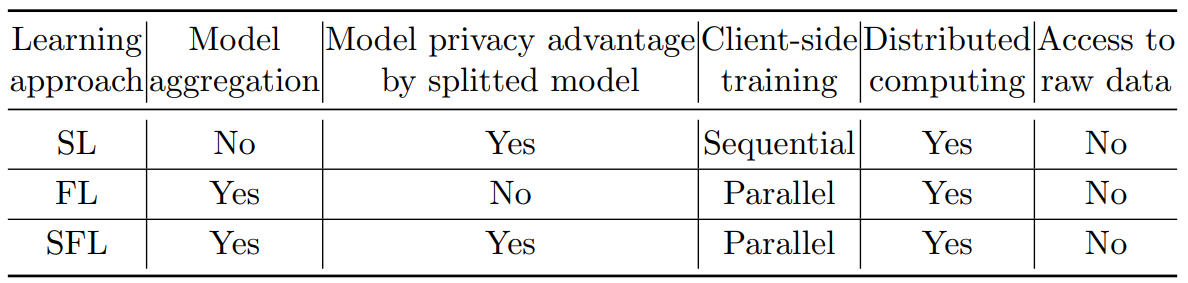
여기에서 특이한 점은, SL을 수행하는 과정에서 Client들이 줄을 서는 일이 발생하지 않는다는 것입니다. 앞서 언급하였듯이, 원래는 오른쪽의 그림[3]처럼 A Client에 대한 학습이 진행되는 동안, B, C Client는 학습을 진행할 수 없었습니다. 하지만 저자들이 제안하는 알고리즘에서는 (비교적) 동시에 SL이 진행되는데, 이것이 가능한 이유는 어차피 Fed Server에서 aggregation을 해야 하므로 굳이 이전 차례에 학습된 정보를 받아오지 않고 개별적으로 학습을 진행하기 때문입니다. 즉, aggregation을 통해서 다른 Client에서 학습된 정보를 가져오기 때문에 같은 일을 두 번 할 필요가 없는 것입니다. 이러한 구조로 학습을 진행함으로써, FL의 문제점인 local device의 제한적인 computation power도 극복하고, SL의 문제점인 느린 학습 속도도 개선하며, 동시에 보안 상에서의 이점도 챙길 수 있다는 것이 저자들의 주장입니다. 아래의 표는 SL, FL, SFL 간의 차이점을 정리한 것입니다.
다음 포스트에서는 SFL의 세부적인 작동 방식에 관하여 알아보도록 하겠습니다.
참고 자료:
[1] [ICML 2019 Workshop] https://aiforsocialgood.github.io/iclr2019/acceptedpapers.htm
[2] [JNCA 2018] https://arxiv.org/abs/1810.06060
[3] [NeurIPS 2019] https://arxiv.org/abs/1912.12115
'Federated Learning > Papers' 카테고리의 다른 글
| [AAAI 2022] SplitFed - (3) (0) | 2022.09.05 |
|---|---|
| [AAAI 2022] SplitFed - (2) (0) | 2022.09.03 |
| [ICLR 2020] Convergence of FedAvg - (7) (0) | 2022.08.30 |
| [ICLR 2020] Convergence of FedAvg - (6) (0) | 2022.08.28 |
| [ICLR 2020] Convergence of FedAvg - (5) (0) | 2022.08.27 |



