
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 기계학습
- OoDD
- deep learning
- Agnostic FL
- OOD
- 머신러닝
- value shaping
- q-FedAvg
- Differential Privacy
- ordered dropout
- Machine learning
- OSR
- data maximization
- 딥러닝
- Fairness
- 연합학습
- Analysis
- 개인정보
- convergence
- DP
- FedAvg
- FL
- PPML
- Open Set Recognition
- q-FFL
- ML
- free rider
- Federated Learning
- Federated Transfer Learning
- FedProx
- Today
- Total
Federated Learning
[CVPR 2021] PROSER - (2) 본문
논문 제목: Learning Placeholders for Open-Set Recognition
출처: https://arxiv.org/abs/2103.15086
지난 포스트에서 OSR의 등장 배경에 간략하게 알아본 후, 기존 OSR 방법들의 문제점을 짚어보았습니다. (이전 글 보기) 이번 포스트에서는 PROSER의 작동 원리에 대하여 알아보도록 하겠습니다.
2. Classifier Placeholder
앞서 정의한 대로 f를 f(x)=WTϕ(x)로 decompose하겠습니다. 저자들은 여기에 추가적인 classifier를 덧붙여서 새로운 hypothesis ˆf을 정의합니다. 즉, ˆf(x)=[WTϕ(x),ˆwTϕ(x)], ˆw∈Rd×1입니다. (이러한 접근은 "처음보는 유형의 data를 unknown으로 분류한다"는 측면에서 직관적입니다.) 여기에서의 관건은 "어떠한 기준에 근거하여 test data를 unknown으로 분류할 것인지"인데, 저자들은 다음과 같은 loss를 제안합니다:
ℓ1:=∑(x, y) ∈ Dtrainℓ(ˆf(x),y)⏟A+βℓ(ˆf(x)∖y,K+1)⏟B
(여기에서, ℓ은 cross-entropy와 같은 임의의 loss function, β는 hyperparameter입니다.) ℓ1은 크게 A와 B, 이렇게 두 components로 이루어져 있는데, A의 경우 우리가 지금까지 계산해왔던 closed-set setting에서의 loss와 크게 다르지 않습니다. (K+1번째 class에서 대해서도 계산을 한다는 정도의 차이만 존재합니다.) 우리가 유심히 보아야 할 것은 B 부분인데, train data x에 대하여 x의 ground truth y를 masking(이는 wTyϕ(x)=0으로 구현합니다)한 채 K+1과의 loss를 계산하고 있습니다. 이와 같이 정의된 \mathcal{B}는 모든 train data가 K+1로 분류될 확률을 두 번째로 높게 만드는 역할을 하고 있습니다. (첫 번째는 당연히 ground truth입니다.)
3. Data Placeholder

다음으로, 학습 과정에서 outlier에 대한 information을 주기 위하여, 저자들은 outlier generation 기법 한 가지를 제안합니다. 이전 포스트에서 generative method들은 추가적인 model이 필요하다는 점, outlier generation에 많은 시간이 요구된다는 점 등을 단점으로 갖고 있다고 언급하였는데, 저자들이 제안하는 방식은 별도의 model이 필요하지도 않고, outlier generation 속도도 크게 뒤처지지 않습니다. 오른쪽 그래프에서, OSRCI와 GFROSR가 generative methods인데, PROSER가 이들보다 더 짧은 시간에 학습되는 모습을 확인할 수 있습니다. (log scale이어서, 실제 차이는 보이는 것보다 더 크고, 오히려 threshold 기반의 OpenMax와 비견할 만 수준의 속도입니다.)
우선, embedding module ϕ(⋅)을 다시 ϕ(x)=ϕpost(ϕpre(x))로 decompose하겠습니다. 즉, ϕpre(⋅)는 처음부터 중간 지점까지, ϕpost(⋅)는 중간 지점부터 끝까지를 나타냅니다. 그다음, 매 mini-batch마다 ground truth가 서로 다른 임의의 두 data xi, xj에 대하여, "중간 지점"에서의 output인 ϕpre(xi), ϕpre(xj) mixup하여 새로운 data ˜xpre를 생성합니다. 다시 말해,
˜xpre:=λϕpre(xi)+(1−λ)ϕpre(xj) where yi≠yj
이며, 여기에서 λ∈[0,1]은 beta distribution을 따릅니다. 그리고 이 ˜xpre를 ϕpost(⋅)에 넣은 결과인 ϕpost(˜xpre)는 결과적으로 어떠한 known class에도 해당하지 않으므로, K+1번째 class로 분류되어야 합니다. 이를 학습하기 위하여, 저자들은 다음과 같은 loss를 제안합니다: (아래의 식에 mini-batch에 관한 부분이 없는데, 실제로는 mini-batch 단위로 outlier를 generate합니다.)
ℓ2:=∑(xi, xj) ∈ Dtrainℓ([W,ˆw]Tϕpost(˜xpre),K+1)
그리고 최종적인 PROSER의 loss function은 ℓtotal:=ℓ1+γℓ2로 표현되며, 여기에서 γ는 hyperparameter입니다.
4. Vanilla Mixup Vs. Manifold Mixup
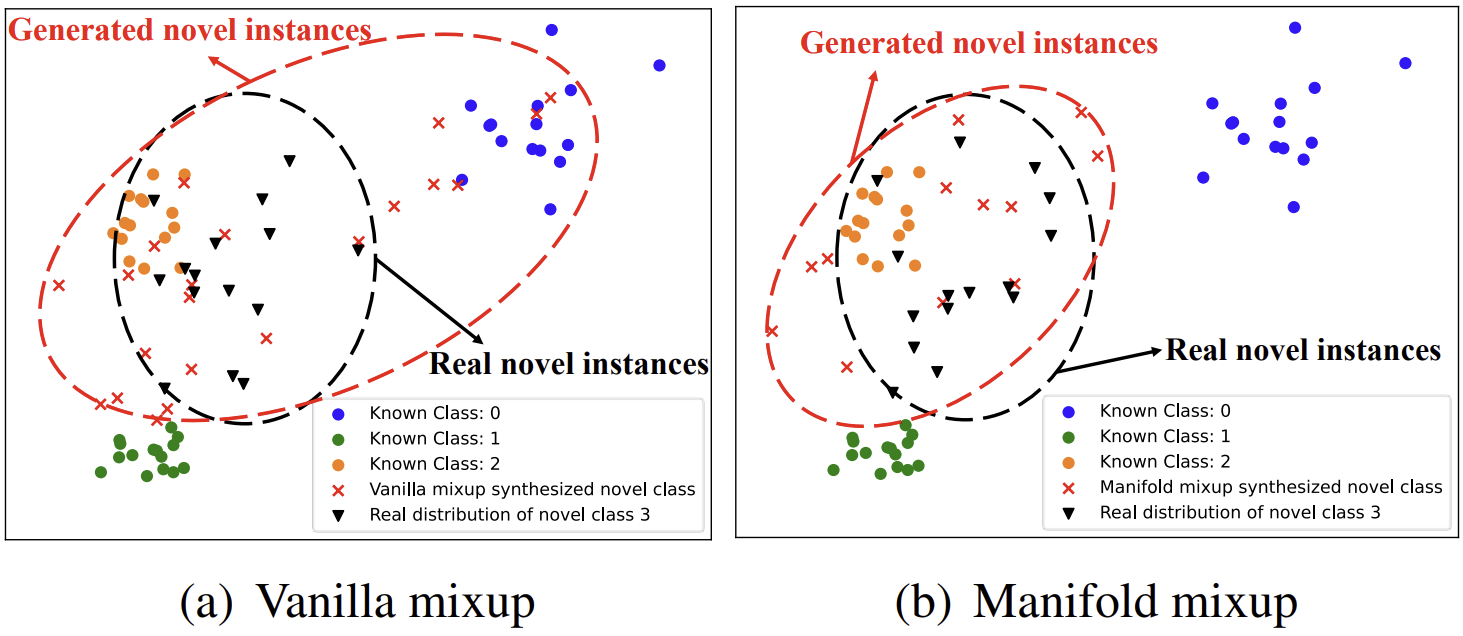
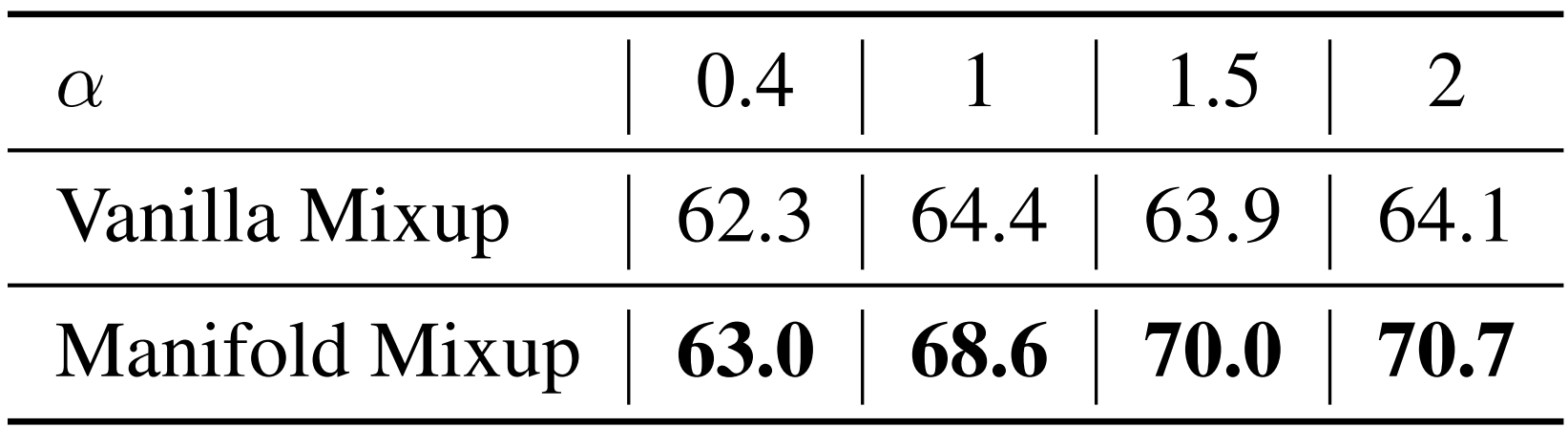
Data Placeholder의 학습 과정을 다시 살펴보면, 학습의 중간 과정에서 서로 다른 class에 속한 두 data를 mixup하는 것을 확인할 수 있습니다. (이를 Manifold Mixup이라고 부르겠습니다.) 날 것의 data 그 자체를 mixup할 수도 있을텐데, 왜 저자들은 이러한 번거로운 과정을 택한 것일까요? 위의 그림을 보면, Vanilla Mixup으로 생성된 outlier들의 distribution이 known class의 distribution과 겹치는 모습을 확인할 수 있습니다. 그리고 이는 실제 unknown data의 distribution과도 어느 정도 떨어져서 존재하고 있습니다. 반면, Manifold Mixup으로 생성된 data의 경우 불필요한 침범을 최소화한 채 실제 unknown data와 비슷하게 분포하고 있는 모습을 볼 수 있습니다. 이는 곧 성능의 차이로도 이어지며, 오른쪽의 표는 λ∼B(α,β)의 α 값을 조절하며 실험한 결과입니다. (CIFAR-100 dataset 중 15개의 class만 known인 상황에서의 macro F1 score입니다.)
다음 포스트에서는 앞서 정의한 두 placeholder가 가져오는 효과와 hyperparameters에 관하여 이야기하도록 하겠습니다.
'Machine Learning > Out-of-Distribution Detection' 카테고리의 다른 글
| [CVPR 2018] Evidential Deep Learning - (1) (1) | 2023.04.29 |
|---|---|
| [CVPR 2021] PROSER - (4) (0) | 2023.03.01 |
| [CVPR 2021] PROSER - (3) (1) | 2023.02.28 |
| [CVPR 2021] PROSER - (1) (0) | 2023.02.17 |


