
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- PPML
- FedProx
- Fairness
- Agnostic FL
- value shaping
- DP
- Open Set Recognition
- ML
- OoDD
- free rider
- FedAvg
- OSR
- FL
- 개인정보
- convergence
- Differential Privacy
- Machine learning
- 머신러닝
- Federated Transfer Learning
- Federated Learning
- 딥러닝
- data maximization
- OOD
- Analysis
- ordered dropout
- q-FedAvg
- 기계학습
- 연합학습
- deep learning
- q-FFL
- Today
- Total
Federated Learning
[CVPR 2021] PROSER - (4) 본문
논문 제목: Learning Placeholders for Open-Set Recognition
출처: https://arxiv.org/abs/2103.15086
지난 포스트를 끝으로 PROSER에 관한 설명을 마쳤습니다. (이전 글 보기) 이번 포스트에서는 experiments를 살펴보겠습니다.
7. Experiments
(1) Openness의 정의
저자들마다 Openess의 정의가 조금씩 다른데, 해당 paper에서는 다음과 같이 정의합니다:
Openness:=1−√NtrainNtest∈[0,1]
여기에서, Ntrain, Ntest는 각각 train dataset과 test dataset의 class 수입니다. 만약 Ntrain=Ntest라면, 이 경우의 Openness는 0이며, 이는 곧 closed set setting임을 의미합니다. 만약 Openness=1라면, 이는 (Ntrain<1일 수는 없으므로) test dataset이 완전히 열려있다, 즉, Ntest→∞라는 의미입니다. 앞서 정의한 대로, 해당 paper에서는 Ntrain=K입니다.
한편, 다음과 같이 Openess를 정의하는 paper도 존재합니다:
Openness:=1−√2×NtrainNtest+Ntarget∈[0,1]
여기에서, Ntarget:=Ntrain+C=K+C인데, 앞선 정의와의 차이점은 hyperparemeter C에 dependent하다는 것입니다. 어떠한 이유로 저자들이 첫 번째 정의를 사용하였는지는 알 수 없지만, C term 외에는 이 둘이 큰 차이를 보이지 않습니다.
(2) Datasets

OSR paper들은 dataset을 known / unknown으로 분할하거나, 두 개의 dataset을 각각 known / unknown으로 설정하고 실험을 진행하는 경우가 많습니다. 오른쪽 표는 해당 paper의 unknown detection (판별 여뷰를 AUROC metric으로 평가) 실험 setting을 정리한 것입니다. OSR (unknown class 1개를 포함한 macro F1 metric으로 평가) 실험의 경우 (i) CIFAR10 (known) / ImageNet or LSUN (unknown), (ii) MNIST (known) / Omniglot or MNIST-noise or Noise (unknown)으로 setting을 구성하였습니다. 오른쪽 그림은 후자를 간략하게 표현한 것입니다.
(3) Unknown Detection
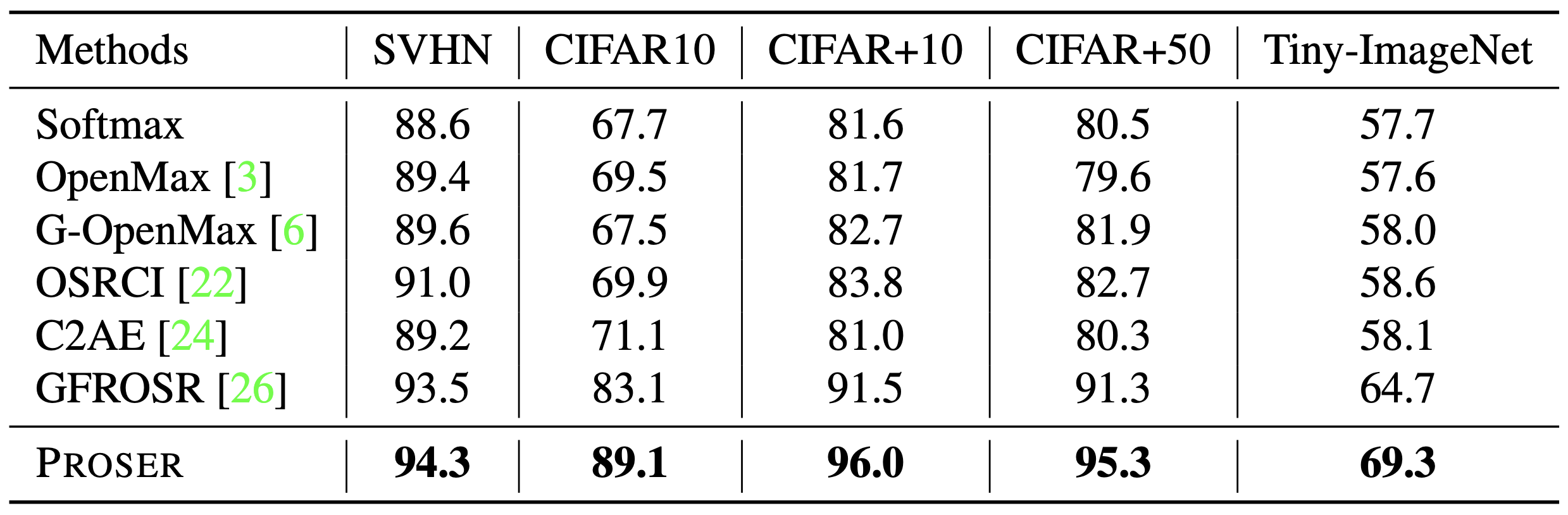
오른쪽 표는 WRN-28-10 model으로 unknown detection을 실험한 결과를 정리한 것입니다. 해당 표의 existing methods에서, 위의 두 개는 (threshold에 기반하는) discriminative 기법이며, 나머지 네 개는 generative 기법인데, 저자들이 제안한 PROSER가 모든 task에 대해서 가장 좋은 성능을 보여주는 것을 확인할 수 있습니다.
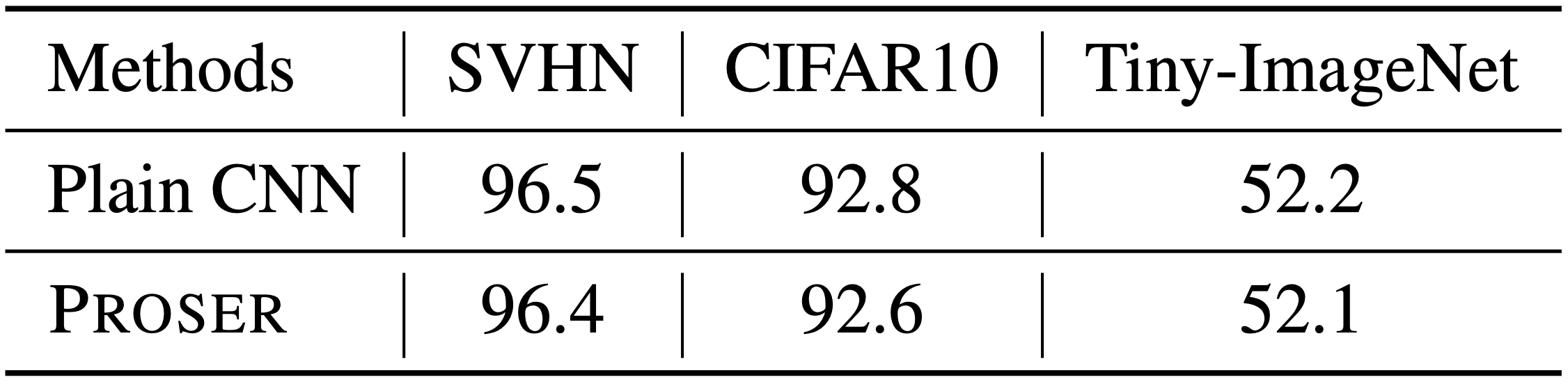
다음의 표는 동일한 아키텍쳐 구성에서 PROSER를 사용하였을 때와 사용하지 않았을 때의 closed set classification 성능 차이를 비교한 것입니다. (accuracy 기준) PROSER의 사용 여부가 성능에 큰 영향을 주지 않는다는 것을 확인할 수 있는 부분입니다.
(4) Open Set Recognition
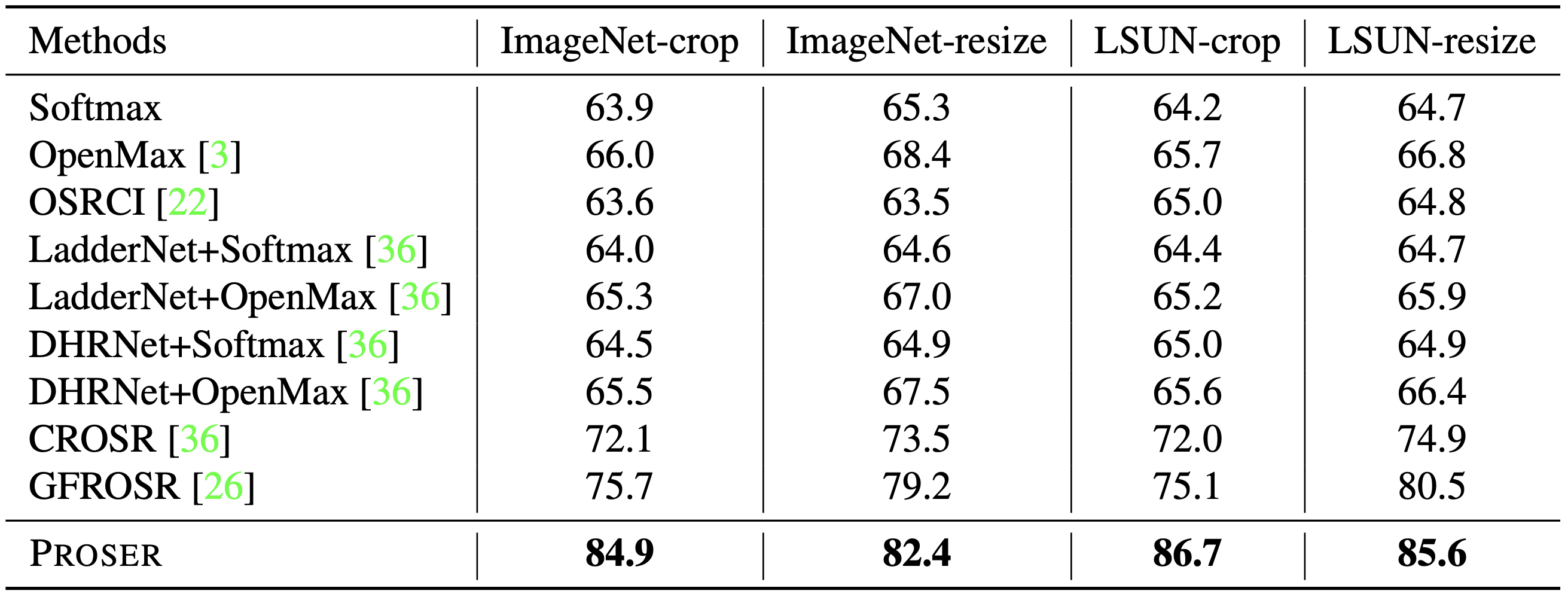
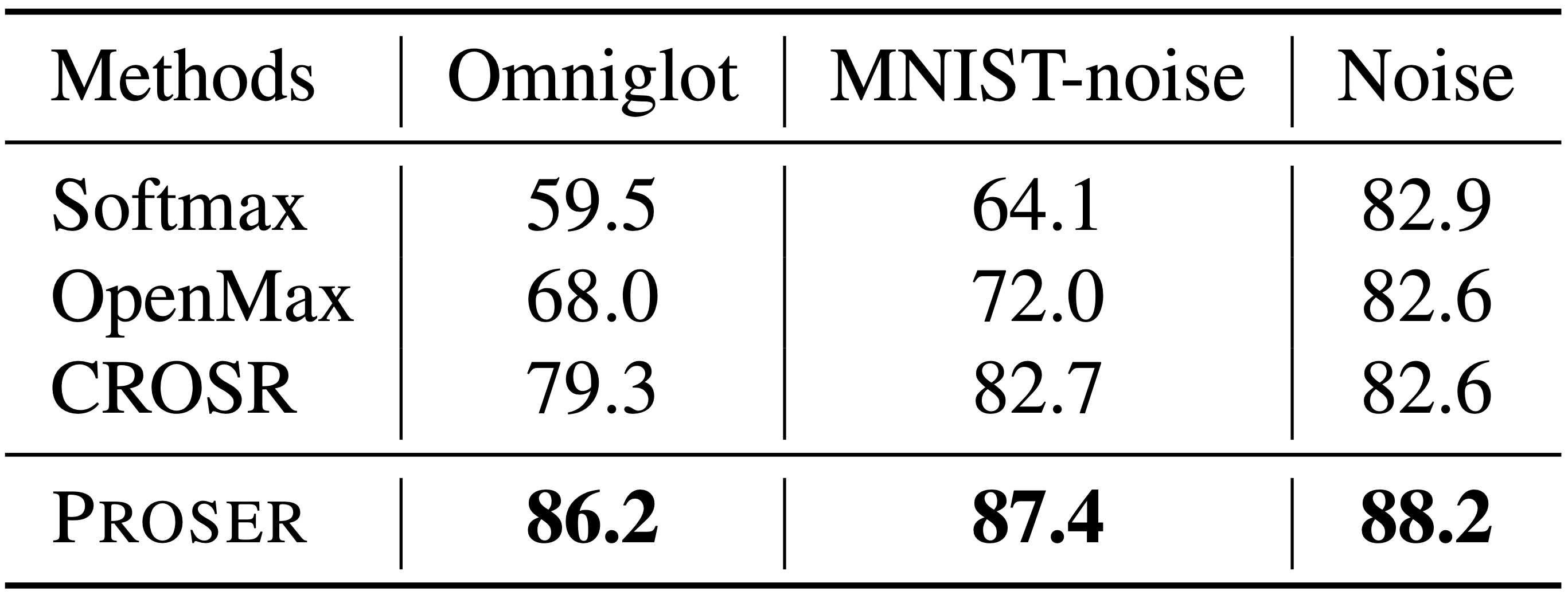
오른쪽 표들은 VGG13 model로 OSR을 실험한 결과를 정리한 것으로, 위의 것은 CIFAR10 (known) / ImageNet or LSUN (unknown), 아래의 것은 MNIST (known) / Omniglot or MNIST-noise or Noise (unknown)에 대한 것입니다. 전자의 경우, ImageNet과 LSUN의 size가 CIFAR10의 size와 달라서 조절이 필요하였는데, 이를 다시 crop과 resize로 구분하여 실험을 진행하였습니다. 7개의 task 모두 PROSER가 가장 좋은 성능을 보여주었는데, 기존 methods과의 성능 차이도 꽤 큰 편입니다.
8. 의의 및 한계
해당 논문은 크게 두 갈래로 갈라져 있던 OSR 방법론들의 문제점들을 동시에 해결하였다는 점에서 의의가 있다고 생각합니다. outlier generation에 요구되는 cost를 현저하게 줄였고, threshold를 heuristic하게 지정할 필요도 없어졌습니다. 해당 paper가 나올 시점에는 크게 흠잡을 점이 없었고, 따라서 oral presentation에 선정되기도 하였으나, 최신 논문들을 보았을 때에는 성능이 많이 따라잡힌 모습 또한 확인할 수 있었습니다. 그럼에도 PROSER는 여전히 경쟁력있는 방법론이라고 생각되며, 별도의 generative model을 사용하기 어려운 환경에서는 특히 괜찮은 선택지 중 하나가 아닐까 싶습니다.
'Machine Learning > Out-of-Distribution Detection' 카테고리의 다른 글
| [CVPR 2018] Evidential Deep Learning - (1) (1) | 2023.04.29 |
|---|---|
| [CVPR 2021] PROSER - (3) (1) | 2023.02.28 |
| [CVPR 2021] PROSER - (2) (0) | 2023.02.25 |
| [CVPR 2021] PROSER - (1) (0) | 2023.02.17 |


