
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- q-FedAvg
- PPML
- FL
- 연합학습
- Differential Privacy
- Agnostic FL
- Fairness
- Analysis
- FedAvg
- ML
- FedProx
- value shaping
- 기계학습
- Open Set Recognition
- Federated Transfer Learning
- DP
- deep learning
- OSR
- q-FFL
- 개인정보
- convergence
- OOD
- Federated Learning
- 머신러닝
- 딥러닝
- Machine learning
- free rider
- data maximization
- ordered dropout
- OoDD
- Today
- Total
Federated Learning
[ICLR 2020] q-FFL, q-FedAvg - (5) 본문
논문 제목: Fair Resource Allocation in Federated Learning
출처: https://arxiv.org/abs/1905.10497

지난 포스트에서 q-FFL의 solver인 q-FedSGD, q-FedAvg에 대하여 알아보았습니다. (이전 글 보기) 이번 포스트에서는 해당 paper의 experiments를 확인해보도록 하겠습니다. 우리가 살펴보아야 할 부분은 q에 따른 성능 변화, 그리고 수렴성입니다.
해당 paper의 경우 experiments가 상당히 길어서, 아쉽게도 모든 실험 결과를 다루지는 못하였습니다. 특히, meta learning에서의 application(q-MAML)은 논의하는 내용을 벗어나서 다루지 않았습니다. 세부 사항은 paper를 참고 바랍니다.
9. Experiments
(1) Dataset
총 4개의 dataset에 대해서, 각각 다른 종류의 architecture를 사용하여 실험을 진행하였습니다. 추가적으로, q=∞와 Agnostic FL을 비교할 때에는 Agnostic FL에서 사용한 두 가지 dataset(Fashion MNIST, Adult)을 그대로 사용하였습니다. Dataset의 statistics와 상세 설명은 다음과 같습니다.
- Synthetic → Linear Regression
- Vehicle → Linear SVM for binary classification
- Sentiment140 → LSTM (Sentiment Analysis)
- Shakespeare → RNN (Next Sentence Prediction)
(2) q=0 Vs. q>0
위 그래프는 각 dataset 별로 q=0일 때와 아래의 표에 나와 있는 q>0일 때의 학습 결과를 비교한 것입니다. 모든 dataset에서 높은 accuracy를 보인 집단의 performance가 감소하고, 낮은 accuracy를 보인 집단의 performance가 증가하는 모습을 볼 수 있습니다. 그리고 그 결과 distribution이 center 쪽으로 조금 더 몰리게 되었습니다. 이는 정확히 q-FFL이 목표로 하였던 바이며, 그와 동시에 average accuracy는 q=0일 때와 동등하거나 오히려 소폭 증가한 것도 눈에 띄는 부분입니다. 또한. uniformity의 경우, 모든 dataset에 대해서, 그리고 모든 uniformify 정의에 대해서 q>0일 때 더 좋은 모습을 보였다는 것을 확인할 수 있습니다.
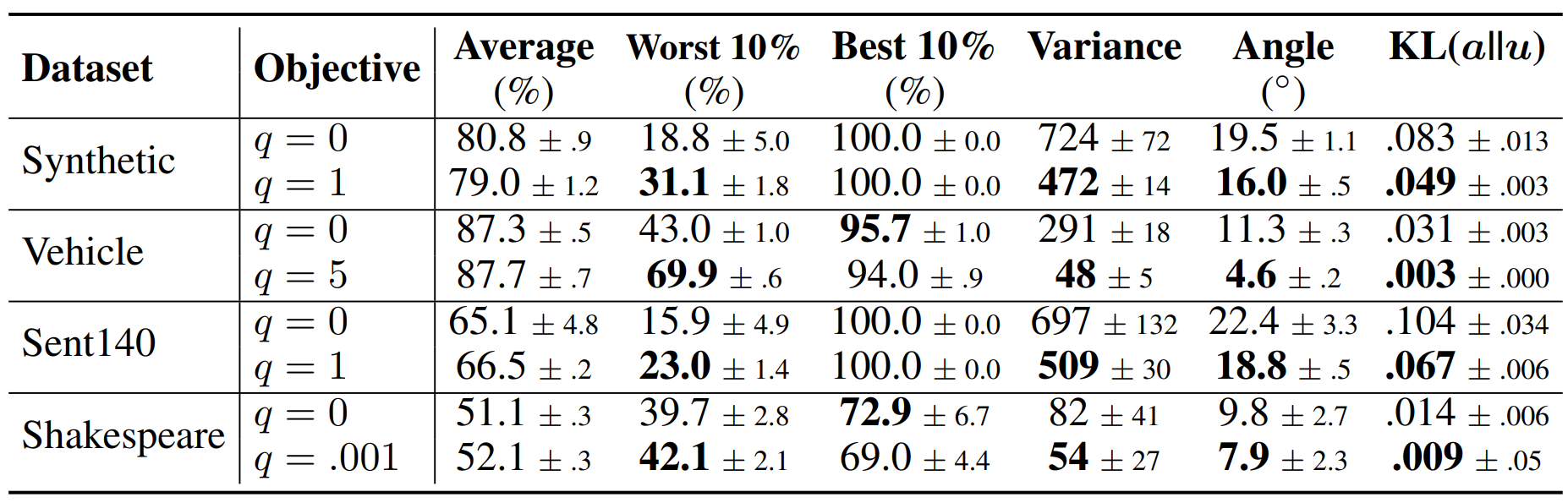
(3) q와 performance 간의 trade-off
다음은, Synthetic Dataset에 대하여 q를 바꾸어가며 실험한 결과입니다. q가 커짐에 따라 전반적으로 uniformity도 함께 증가하는 모습을 보이나, 그만큼 trade-off도 크다는 것을 확인할 수 있습니다. 특히 q=5의 경우, Worst 10%의 성능과 uniformity가 감소하는 모습을 보입니다. 이 부분을 통해 q를 무작정 키우는 것이 능사가 아니라는 것을 단적으로 알 수 있습니다.

(4) client 별로 다른 q를 지정하기
다음은, 각 client마다 local computation을 통해서 적절한 q를 지정해준 결과를 보여줍니다. 더 많은 계산이 요구되므로 사실 더 좋은 성능을 보여주는 것은 당연합니다만, communication round가 진행되기 전까지 남는 시간 동안 local에서 tuning이 진행될 것이라는 점을 감안하면, 시간적인 부분에서 생기는 손해는 없을 것입니다.

(5) q-FFL Vs. Agnostic FL
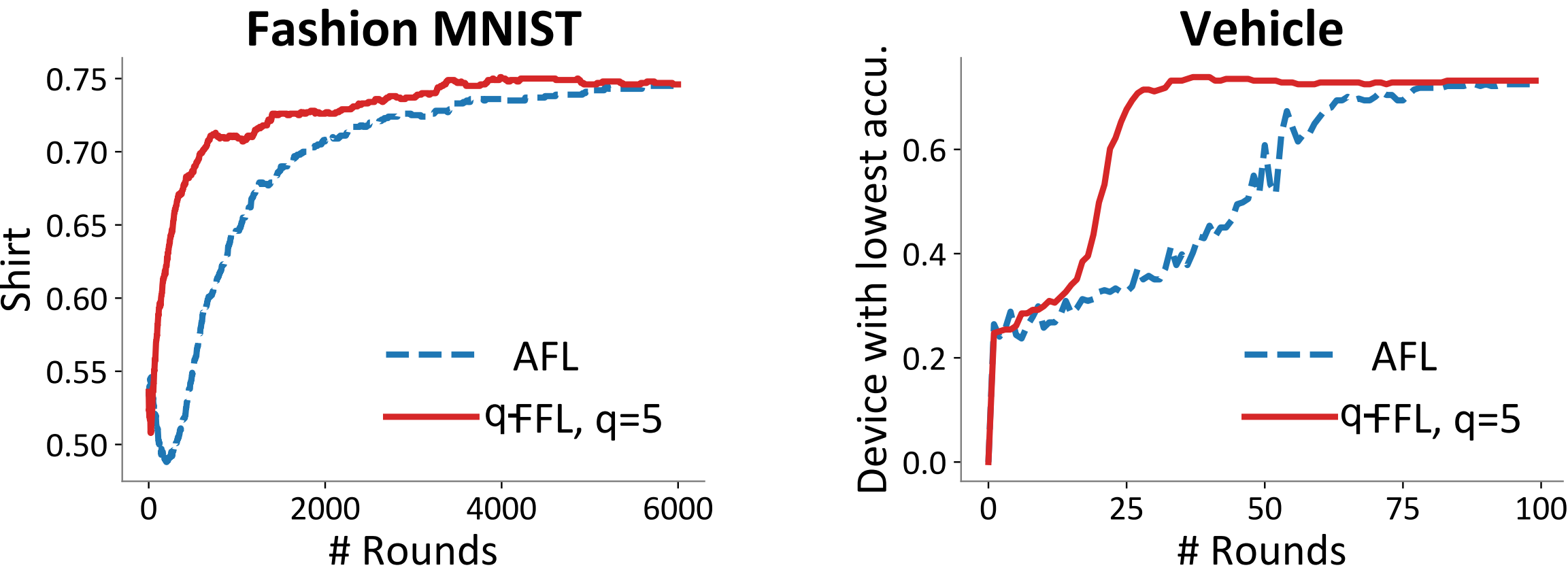
Fashion MNIST는 3개의 device가, Vehivle은 23개의 device가 학습에 참여한 상황입니다. 그리고 그중 가장 안 좋은 performance를 보여주는 각 device에 대한 학습 결과는 다음과 같습니다. 학습에 참여하는 device의 수가 많은 상황(Vehicle)에서 Agnostic FL이 정상적으로 학습하기 어렵다는 것을 기존 paper를 통해서 알고 있었는데, q-FFL은 Agnostic보다 더 빠르게 수렴하는 모습을 보입니다. 다만, 학습에 필요한 round 수가 줄어든 것 자체도 충분히 의미가 있지만, 왜 결국 두 알고리즘의 accuracy가 수렴하는지에 대한 설명은 조금 부족해보입니다. 그리고 저자들이 q-FedSGD와 q-FedSGD 중 무엇을 사용하였는지에 대해서는 언급하지 않았습니다.
(6) q-FedAvg가 실제로 효율적인지

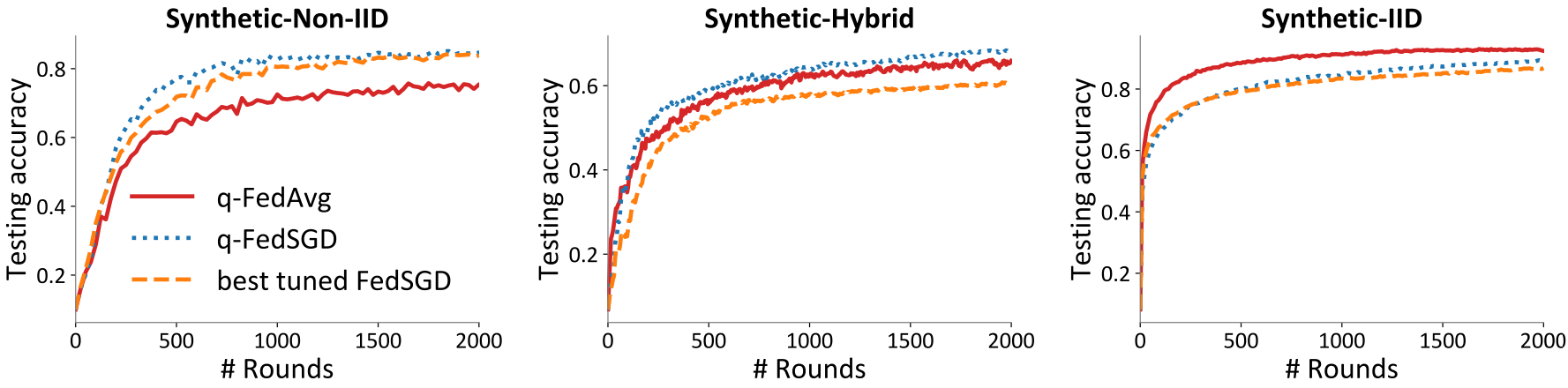
위 그래프는 FedSGD, q-FedSGD, q-FedAvg 간의 성능 차를 비교한 것입니다. 특이한 점이 있다면, Synthetic Dataset에서 q-FedAvg가 유의미하게 낮은 성능을 보여준다는 것입니다. 저자들은 이 부분을 "Synthetic Dataset의 경우, local distribution들이 매우 heterogeneous하기 때문에 local update 과정에서 global model과 많이 멀어지게 되는 것 같다"고 설명하고 있습니다. 이는 마치 FedAvg에서 보았던 현상과 동일합니다. 아래의 그래프는 Synthetic Data를 다시 IID / Hybrid / Non-IID로 구분지어 실험한 결과인데, IID case에서는 q-FedAvg가 가장 좋은 performance를 보여주지만, Non-IID case(위 그래프와 Synthesis와 동일한 실험입니다)에서는 q-FedAvg가 가장 나쁜 performance를 보여주고 있습니다. 즉, heterogeneity가 과도하게 커질 경우 q-FedAvg는 제 성능을 못 낼 가능성이 농후하며, 이 부분은 개선되어야 할 필요가 있습니다.
(7) q의 값에 따른 수렴성 비교

q>0를 사용한다는 것은 곧 optimization이 더 어려워진다는 것을 의미합니다. 저자들은 이 부분을 q-FedAvg 기준으로 확인해보았는데, 다행히도 q=0인 경우와 convergence의 속도가 크게 차이나지 않는다는 것을 위 그래프를 통해서 확인할 수 있습니다. (물론, 앞서 살펴보았듯이, Synthetic Dataset의 경우 converge하는 데에 어려움을 겪는 모습을 보입니다.)
10. 의의 및 한계
Agnostic FL이 가지고 있던 문제들(client 수가 많아지면 학습이 어려워지고, worst performance를 보여주는 한 개의 client에 대해서만 보정이 이루어진다는 점)을 Agnostic FL을 generalization함으로써 해결하였다는 점이 해당 paper의 의의라고 할 수 있습니다. 그리고 generalization 과정에서 uniformity를 비교할 수 있는 다양한 metric(variance, cosine similarity, entropy)을 제시하였다는 점 역시 주목할 만합니다. 다만, Federated Learning이 일반적으로 local distribution들의 heterogeneity를 가정한다는 점을 고려했을 때, 개선해야 할 여지가 아직은 어느 정도 남아 있다고도 볼 수 있습니다.
'Federated Learning > Papers' 카테고리의 다른 글
| [FL-NeurIPS 2022] Data Maximization - (2) (0) | 2023.01.03 |
|---|---|
| [FL-NeurIPS 2022] Data Maximization - (1) (0) | 2022.12.13 |
| [ICLR 2020] q-FFL, q-FedAvg - (4) (0) | 2022.12.07 |
| [ICLR 2020] q-FFL, q-FedAvg - (3) (0) | 2022.11.30 |
| [ICLR 2020] q-FFL, q-FedAvg - (2) (0) | 2022.11.27 |


